There's a particular kind of marketing irony that keeps me up at night, and not the good, thought-provoking kind. It's watching brands pour serious budget into "AI-ready content strategies" while their own security infrastructure is quietly turning away every AI crawler that shows up at the door.
I've been running late-night technical audits on enterprise websites lately (yes, voluntarily, postgraduate modules and an unhealthy relationship with coffee will do that to you). After going through hundreds of sites under the hood, a pattern becomes impossible to ignore: companies are agonising over their AI-friendly tone of voice while their technical architecture is actively locking the front door on the bots they most want citations from.
This isn't a content problem. It's a systems problem.
We've moved past optimising for human browsers and standard search indexers. There's a third layer now, the raw access points that feed real-time LLM answers. If your site makes an AI engine work too hard to extract a basic fact, it doesn't complain or retry. It just pulls from a competitor who made it easy.
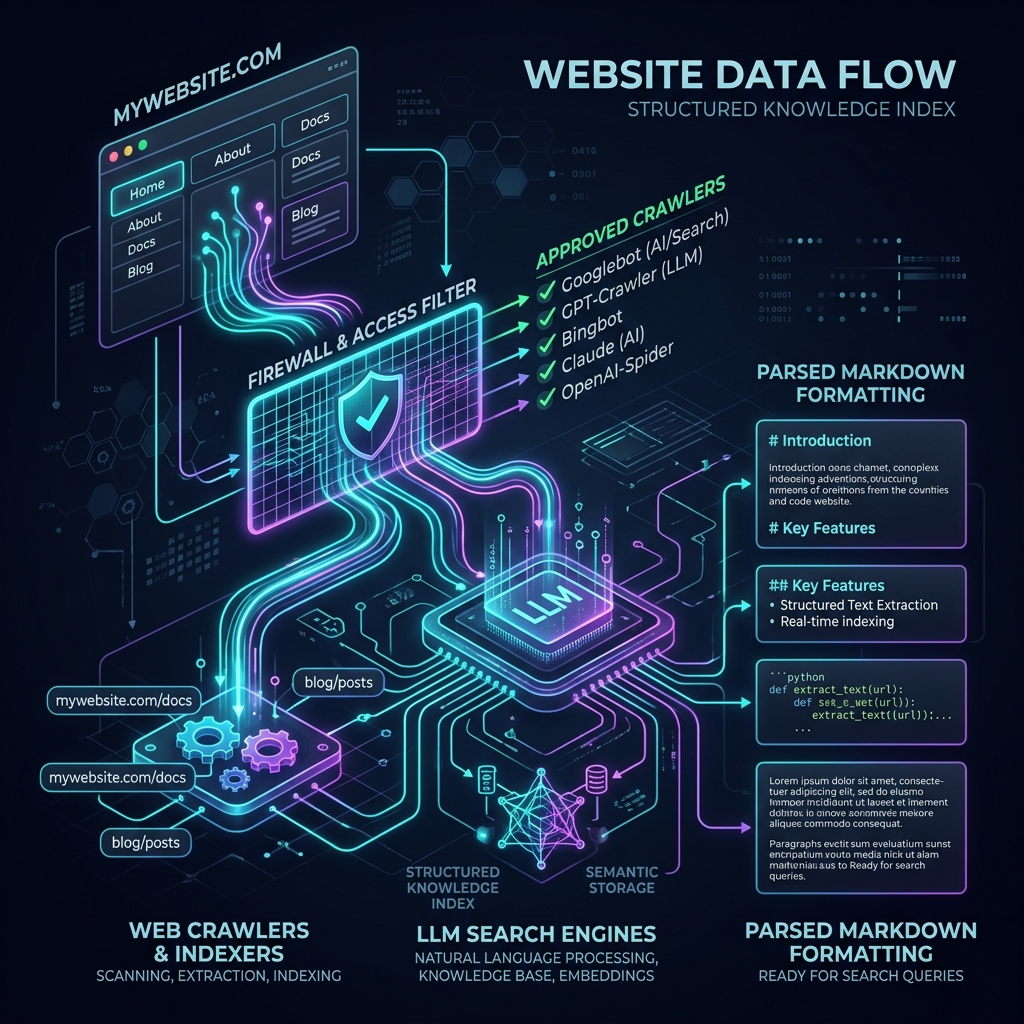
1. Your firewall doesn't know the difference between a bad bot and a good one, so teach it
The most common thing I see breaking AI discoverability: Cloudflare and equivalent security layers set to block high-frequency scrapers by default. Sensible, in theory. Catastrophic in practice, because LLM retrieval agents hit that same tripwire.
An AI crawler will not solve a CAPTCHA. It won't identify the traffic lights or click the bicycle. It will simply fail, log your domain as inaccessible, and the next brand answer it pulls will be your competitor's.
The fix isn't to open everything up. Plenty of bots genuinely are just hoovering your content to train models, and you don't owe them that. The decision worth making is more surgical: selectively whitelist the live-retrieval agents (OAI-SearchBot, PerplexityBot, Claude-Web) that actually drive referral traffic back to your pages, while keeping the bulk training scrapers blocked. Your developers can manage this at the firewall level once you know which agents you're targeting.
It takes an afternoon. The cost of not doing it compounds quietly, every day.
2. An llms.txt file is the simplest thing you're probably not doing
Think of it as an executive summary written for a machine. Where an XML sitemap is every URL you've ever published thrown into a pile, an llms.txt file is a lightweight markdown document sitting at your domain root: purposeful, readable, and pointing AI agents directly to your most valuable content.
It signals intent. It reduces guesswork. And it takes less time to set up than most of the content strategy meetings I've sat through.
Here's how to actually get it live:
- Step 1: Create the file: Open a text editor. Create a file named exactly
llms.txt(lowercase). Start with a heading that states your brand name, followed by a factual one-paragraph description of what your business does. Not a brand statement. Not a tagline. A clear, parseable description of what user problems you solve. - Step 2: Map your highest-value pages: List your core service pages, original research, and primary strategy resources. Omit legal boilerplate, paginated tags, and anything that doesn't directly answer a commercial question. Bots have processing limits. Don't waste them on your cookie policy.
- Step 3: Write one-sentence descriptions per link: Under each URL, add a single sentence explaining which specific user query that page answers. Write it plainly. Drop the promotional language entirely — machines parse dry, direct text far better than copy written to impress a human reader.
- Step 4: Deploy and set content type: Upload to your public root directory. Confirm your server is delivering it as clean plain text. That's it. It's live.
3. Stop designing pages for humans and then hoping AI can read them too
When an LLM pulls from your site to answer a query, it's not admiring your layout. It's trying to locate structured, extractable information as fast as possible. If your data is inside a dynamic chart, your key insights are buried 1,800 words into a long-form piece written to maximise scroll depth, and your navigation only loads correctly via JavaScript, you've built a beautiful room with no windows.
| Website Element | Traditional Approach | AI-Optimised Approach |
|---|---|---|
| Data and metrics | Embedded in graphical charts or images | Hardcoded in clean HTML tables or markdown |
| Key takeaways | Distributed across a long article | Bulleted and placed directly below the section header |
| Site navigation | Multi-tier JavaScript menus | Plain text footer map with explicit anchor links |
The shift here isn't about dumbing down your content. It's about structuring the same insight so a machine can find and verify it in seconds, not minutes because it won't wait minutes.
The actual point
Technical optimisation for AI isn't about gaming a system. It's about removing the friction between your best thinking and the engines that are increasingly deciding whose thinking gets surfaced.
If a generative search engine can fetch, read, and cite your content reliably, your brand becomes the trusted source it displays to the buyer before a competitor's site ever appears. That's not a trick. That's the same principle that made technical SEO matter in the first place, applied to a new layer of the stack.
The sites that figure this out early aren't going to look clever in hindsight. They're just going to have a head start that quietly compounds.
